Large Language Models (LLMs) have stormed into the research and learning landscape with incredible promise. As an AI researcher and educator, I often find myself torn between excitement and caution. On the one hand, LLMs like ChatGPT and its peers are astonishingly powerful – capable of generating code, explanations, and ideas in seconds. On the other hand, I worry about a growing temptation to outsource thinking to these models. I approach this discussion with strong opinions, loosely held – I’ll state my views confidently, but I’m ready to adjust them as I learn more. In that spirit, let’s explore how LLMs can be amazing accelerators for experienced users while potentially becoming crutches that hamper genuine learning among students.
LLMs: Accelerators for Experts, Not Shortcuts for Students
It’s clear that expert researchers and developers can leverage LLMs as productivity boosters, while less experienced students might misuse them as cheat codes. An expert programmer, for example, might use an LLM to save time on boilerplate code or to get a quick refresher on an API – essentially treating the LLM as an accelerator. Because of their strong foundation, they can critically assess the AI’s suggestions and integrate them appropriately. In contrast, a student still learning the ropes might be tempted to have the LLM do their homework. This is where the alarm bells ring: if a beginner relies on the AI to solve problems for them, they skip the struggle that builds intuition and skill. One experienced engineer put it succinctly: you still need solid fundamentals and intuition when using an LLM, otherwise “you’re at the same whims of copypasta that have always existed” . In other words, without prior knowledge, a student using an LLM may simply copy answers without understanding – the age-old trap of imitation without comprehension, now turbocharged by AI.
Students need to work through problems independently – an essential part of learning that no AI should replace. In my teaching philosophy, I emphasize that struggle isn’t a bug; it’s a feature of learning. Wrestling with a tough math problem or debugging code for hours can be frustrating, but it develops critical problem-solving skills and deep understanding. If a student bypasses that process by asking an LLM for the answer, they might get the solution right now but lose out in the long run. Recent research backs this up: high schoolers who used ChatGPT to help on practice problems solved more exercises correctly in practice, but scored significantly worse on the real test . Why? Because the AI became a crutch – the students weren’t developing their own problem-solving muscles. The researchers bluntly titled their paper “Generative AI Can Harm Learning,” noting that students with AI assistance often just asked for answers and failed to build skills on their own. This cautionary tale reinforces my stance: students need to learn to think, not just to prompt an AI.
Debugging the AI: The Challenge of Trusting LLM Outputs
One big hurdle with LLM-generated content is debugging or verifying it – especially for beginners. When an LLM writes code or explains a concept, it does so with supreme confidence (and no indication of uncertainty). A novice might be completely oblivious if that code has a subtle bug or the explanation has a slight error. The illusion of correctness is strong – the answer sounds authoritative. Seasoned experts usually approach AI output with healthy skepticism: they test the code, double-check facts, and use their experience to sniff out nonsense. A beginner, however, might take the output at face value and run into trouble when things don’t work. Debugging someone else’s (or something else’s) solution can be harder than doing it yourself from scratch. I’ve seen students struggle to fix code that “the AI told them would work,” feeling lost because they don’t understand the solution enough to tweak it. This scenario can be more time-consuming and discouraging than if they’d tried it themselves initially.
In the coding context, a darkly funny saying is circulating: “AI isn’t a co-pilot; it’s a junior dev faking competence. Trust it at your own risk.”. That captures the situation well – LLMs sound confident but can make rookie mistakes. For an experienced coder, the LLM is like a junior assistant who needs supervision. For a novice, that “assistant” might confidently lead them off a cliff regarding a buggy approach or a misinterpreted concept. The challenge, then, is teaching learners to not blindly trust LLM outputs. They must learn to ask: “Does this answer make sense? Why does this code work (or not)? Can I verify this claim?” Without that critical eye, using LLMs can become an exercise in blind faith – the opposite of the analytical mindset we aim to cultivate in education.
Quick Answers vs. Deep Understanding
There’s also a qualitative difference between skimming an AI-generated answer and engaging in deeper learning through traditional resources. I’ll admit, it’s incredibly tempting to fire off a question to ChatGPT and get a neatly packaged answer, rather than digging through the official documentation or searching forums. It saves time in the moment. But I’ve found that what I gain in speed, I often lose in depth. Reading official documentation or a detailed StackOverflow thread might take longer, but it exposes me to the why and how, not just the what. Often, those sources include caveats, different viewpoints from commenters, or related tips that an LLM’s single answer might gloss over.
In fact, one developer quipped that LLMs are “a more fluent but also more lossy way of interfacing with Stack Overflow and tutorials.” The AI might give you a quick synopsis of what’s out there, but it can lose nuance and detail – kind of like reading only the summary of a long discussion. When a topic is well-covered on forums or documentation, an LLM can indeed fetch a quick answer tailored to your question. However, if the topic is unusual or not well-represented in the training data, the AI may give you irrelevant or incorrect info (“circular nonsense,” as that developer said). By contrast, if you take the time to read through documentation or ask peers, you can usually piece together a correct solution and also understand the context. I personally recall many times when slogging through a tricky manual or a long Q&A thread taught me things I didn’t even know I was missing. Those “Aha!” moments often come from the deeper dive, not the quick skim. So, while LLMs can serve up answers on a silver platter, there’s a richness in traditional learning methods that we shouldn’t lose. Quick answers have their place – especially when you already grasp the fundamentals – but for true learning, there’s no real substitute for digging in and doing the reading and thinking.
LLMs as a Tool, Not a Necessity
All that said, I’m not advocating we throw out LLMs entirely. Far from it! I see them as valuable tools – just not essential ones for learning. We should treat access to LLMs similarly to how we treat access to power tools in a workshop. A power drill is incredibly useful and can speed up construction, but a good carpenter still needs to know how to use a hand tool and understand the building principles; not every task requires the electric drill. Likewise, an LLM can accelerate certain tasks for a knowledgeable user, but a student should first learn how to hammer nails (solve problems) by hand before reaching for the power drill of AI. If one doesn’t understand the basics, the fancy tool can be detrimental or dangerous.
It’s also worth noting that LLMs are a convenience, not a right or requirement. Many of us learned skills and completed research long before these models existed. Students today should view ChatGPT or similar AI as an optional aid that can occasionally help clarify or inspire – not as a default first step for every problem. In fact, sometimes, I encourage students to pretend they don’t have access to an AI assistant to simulate real problem-solving conditions. If they get truly stuck after earnest effort, then using an LLM as a tutor or to get a hint is fine. But immediately resorting to the AI at the first sign of difficulty can become a bad habit.
Another practical aspect is that the AI landscape is rapidly evolving and chaotic. There’s a diversity of tools available now, with new models and versions coming out all the time – and it’s not apparent which one is best for a given task. For example, today we have:
OpenAI’s GPT-4 (ChatGPT) is a leading model known for its strong capabilities. It is often used for complex tasks (though it requires a subscription or access and has limits).
Between me writing this post and publishing it, Grok.com model version 3 became generally available, and it beat out all other models in every benchmark.
Google Bard – another conversational AI that is freely accessible and integrates some up-to-date information but might lag in coding accuracy compared to GPT -4.
Anthropic’s Claude – an AI with a very large context window (great for feeding lots of text) but less commonly available.
Open-source LLMs (e.g., LLaMA 2, Falcon, etc.) are models you can run or fine-tune yourself. They offer flexibility and privacy but require technical know-how and often lack the quality of top-tier models.
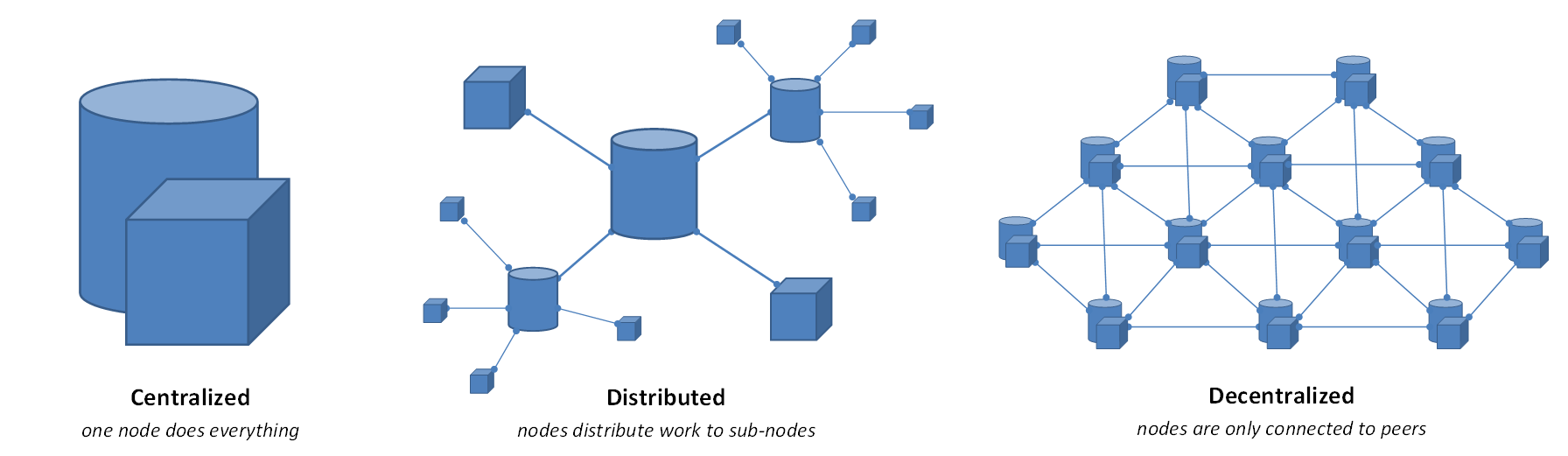
This zoo of AI models means that there’s no single standard tool everyone must use – and each comes with trade-offs. The “best” choice can depend on the task, personal preference, or even ethical considerations (like keeping data private). Given this uncertainty, I view LLMs as helpful accessories in learning rather than core essentials. If a student doesn’t have access to GPT-4, it’s not the end of the world – they can still learn effectively via textbooks, websites, and their reasoning. Conversely, having the fanciest AI doesn’t automatically make one a better learner or researcher; it always depends on how you use it.
Guidelines for Use: Finding the Balance
So, what’s the practical way to balance leveraging LLMs and ensuring real learning happens? My current recommendation (admittedly a strong opinion, loosely held) is a somewhat conservative approach: do not provide students automatic access to LLMs in official learning settings, but don’t ban them outright. In our lab, for instance, I don’t hand out ChatGPT accounts or integrate an AI into the core curriculum. Students are expected to grapple with assignments using their minds (and resources like books, notes, and the internet). If they choose to consult an LLM on their own time, that’s their decision – but we don’t encourage it or build our teaching around it. This approach conveys that we value the learning process over just getting the answer. It also avoids any notion that using the AI is “required” or officially endorsed, which might make some students uncomfortable or overly reliant.
For researchers and more advanced learners, I take a case-by-case stance. In research, time is precious, and the problems are often open-ended. If an LLM can speed up a literature review, help brainstorm experimental designs, or even generate some boilerplate code for data analysis, I’m open to its use. The key is that the researcher must remain in the driver’s seat. We evaluate: Does using the LLM meaningfully benefit the project? Are we double-checking whatever it produces? In some cases – for example, when writing a quick script to format data – using AI is a harmless shortcut. In other cases – like deriving a critical formula or core algorithm – it might be too risky to trust the AI or simply crucial for the researcher’s growth to solve it manually. We also consider ethical and privacy factors: feeding proprietary research data into a public AI may be a bad idea, for example. There’s no one-size-fits-all rule here; it requires judgment. But broadly, students and beginners get more restrictions (for their own good), while experienced folks have more leeway with careful oversight.
(I am writing this while I have the capability to infer at 8 tokens per second on my own Deepseek R1 model – so privacy can be debated.)
My Personal Approach (Strong Opinions, Loosely Held in Action)
To lay my cards on the table: I’m not just preaching from an ivory tower – I actively grapple with how I use LLMs in my daily work. I’ll share a personal approach that reflects the balanced philosophy I’ve been discussing. I do use ChatGPT (and other LLMs) as a kind of writing and brainstorming partner. For example, when drafting narration scripts for a presentation or exploring how to phrase a concept clearly, I’ll have a chat with the AI. It’s fantastic for generating a few different ways to explain an idea, or even giving me a rough narrative flow that I can then personalize. In those cases, I treat the LLM like a collaborator who helps me articulate thoughts – it genuinely accelerates my work without detracting from my understanding (since the experience must first come from me to guide the AI).
However, when it comes to coding or solving research problems, I deliberately stay “hands-on”. If I’m learning a new programming language or tackling a tricky bug in my code, I resist the urge to ask the AI to fix it for me. I’m refining my skills and reinforcing my knowledge by working through it myself. It’s slower and sometimes more painful, but it’s the productive struggle I believe in. I often remind myself that every error I debug and every algorithm I write from scratch is an investment in my future abilities. Using AI to do those things for me would feel like cheating myself out of learning. So in practice, I use LLMs for acceleration in areas where I’m already competent(writing, summarizing, ideating), and avoid using them as a crutch in areas where I’m still growing (learning new tech, building intuition in a domain). This personal rule of thumb has served me well so far – it lets me enjoy the benefits of AI augmentation without losing the satisfaction (and long-term benefits) of doing hard things on my own.
Conclusion: Proceed with Caution and Curiosity
In closing, I maintain that LLMs are potent allies in modern research and learning – but we must engage with them thoughtfully. As an educator, I want to produce thinkers and problem-solvers, not just people who can play “20 questions” with an AI until it spits out an answer. The long-term effects of widespread LLM use on learning and cognition are still unknown. Will students of the future struggle to think independently if they grow up always consulting an AI? Or will they reach even greater heights by offloading tedious tasks to machines and focusing on creativity? We don’t fully know yet. That uncertainty is precisely why a critical, go-slow approach feels right to me at this stage. Let’s use these fantastic tools and constantly ask ourselves why and how we’re using them. By holding our strong opinions loosely, we stay open to change: if evidence down the line shows that deeper LLM integration improves learning without drawbacks, I’ll happily adapt. This is written from the vantage point of being exposed to ChatGPT3 through all models since March 2025, not vantage enough at all in the scale of AI model development. Until then, I’ll continue championing a balanced path – one where human intuition, struggle, and insight remain at the center of learning, with AI as a supportive sidekick rather than the star of the show. After all, the goal as an educator is to get answers faster and cultivate minds that can understand and question the world – with or without an LLM whispering in our ear.